Decoding the confusing world of encodings (Part 2)
This post originally appeared on dev.to
What is an encoding? Part 2
In part 1 we demystified the following ways the term "encoding" is used:
This file is hex encoded
This file uses an ASCII encoding
This string is Unicode encoded
Let's write the output to a UTF-8 encoded file
In part 2 we'll address the remaining ways "encoding" could be used:
Our message is safe because it's encoded using Base64
Python uses Unicode strings for encoding
Our message is safe because it's encoded using Base64
This statement deals with several different concepts. I'll start by going over the types of encoding.
As best as I can tell there are 2 different categories for encoding: character encodings and binary-to-text encodings. ASCII and UTF-8 are examples of character encodings. Base64 is an example of a binary-to-text encoding.
What's the difference? Both character encodings and binary-to-text encodings share the same goal of turning bits into characters. However, character encodings are designed to produce human-readable output. Binary-to-text encodings are designed to turn bits into human-printable output.
Wait, what? That was a nebulous distinction you say? Okay, let me try to explain it in a different way. A character encoding like ASCII is really good for data storage and transmission. For example, say you're writing a speech. You want to save it on your computer so you don't have to re-type it every time. The computer stores that speech as a bunch of 1s and 0s. ASCII is needed to translate those bits back into the words, letters, and punctuation that make up the speech. In the same way, say you want to upload the speech to the cloud. The exact same process is needed to transport that speech over the Internet.
Base64 is an example of a binary-to-text encoding. In fact, it's pretty much the only one in use, much like UTF-8 is for character encodings on the web. It is a subset of ASCII, containing 64 of the 128 ASCII characters: a-z, A-Z, 0-9, +, and /. It doesn't contain characters like NUL or EOF (which are examples of non-printable characters). Base64 is often used to translate a binary file to text, or even a text file with non-printable characters to one with only printable characters. The benefits of this are that you can output the contents of any type of file, no matter what data it contains. It doesn't have to be limited to a file either; it can be just a string, such as a password. Also, you are guaranteed to always have characters that can be displayed, no matter what the underlying bits are. That is something UTF-8 cannot accomplish. How does Base64 do it?
I described in the UTF-8 section in part 1 how certain bit patterns at the start of a byte indicate how many bytes the character will be. 0 for 1 byte, 110 for 2 bytes, 1110 for 3 bytes, and 11110 for 4 bytes. And it uses 10 to indicate a byte is a continuation byte. This means that byte sequences that don't follow this pattern are incomprehensible to UTF-8. A byte that doesn't start with 0, 10, 110, 1110, or 11110 wouldn't be rendered properly by UTF-8. For example, UTF-8 doesn't understand 11111111.
Let's show this on the command line with a new file, file3.txt:
$ cat file3.txt
123
$ xxd -b file3.txt
00000000: 00110001 00110010 00110011 00001010 123.
$ printf '\xff' | dd of=file3.txt bs=1 seek=0 count=1 conv=notrunc # overwrite the first byte with 11111111
1+0 records in
1+0 records out
1 byte copied, 0.0009188 s, 1.1 kB/s
$ xxd -b file3.txt
00000000: 11111111 00110010 00110011 00001010 .23.
This is what the file looked like in VSCode using a UTF-8 encoding before being overwritten with the printf '\xff' | dd... command:
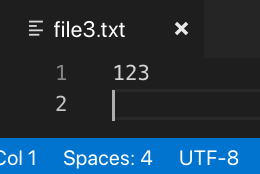
And this is what it looked like after:
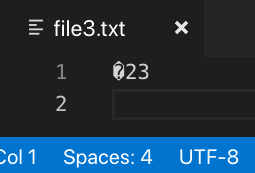
As mentioned before, Base64 can always display printable characters, even when UTF-8 cannot. Let's see that in action:
$ base64 file3.txt > file4.txt
And now the file has printable characters:

Okay, great. But how did we end up with /zIzCg==? I'll take this one step at a time to avoid confusion.
Base64 has 64 characters in its alphabet. That means it only needs 6 bits to represent the whole alphabet (26 == 64). UTF-8 uses the leading bits in a byte as metadata to determine whether it's a starting byte or a continuation byte. Those bytes don't hold any information about the character being stored (i.e., the actual data). In contrast, Base64 uses the entire byte as data. It has no metadata. However, as I mentioned it only uses 6 bits. A byte has 8 bits. How does this math line up?
Let's start by examining the Base64 table, which looks very similar to the ASCII table:
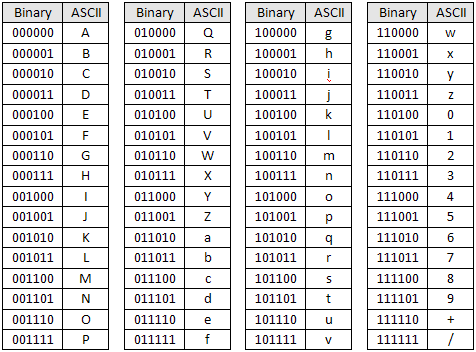
file3.txt's binary representation is 11111111 00110010 00110011 00001010. The way Base64 works is to interpret the bits in groups of 6. So even though the logical grouping of a byte is 8 bits, we're going to modify the groupings to be 6 bits (to reflect how Base64 sees this): 111111 110011 001000 110011 000010 10. In fact, let's look at it in a table format to make things easier:
| Bytes | Base64 character |
|---|---|
111111 | / |
110011 | z |
001000 | I |
110011 | z |
000010 | C |
10 | ??? |
The first 5 groupings of 6 bits line up perfectly with the first 5 characters of our Base64 encoded file4.txt. But we only have 2 bits remaining at the end, which is not enough to make a valid character in Base64. file3.txt had 4 bytes, which is 32 bits. 32 is not divisible by 6.
When a file size is not divisible by 6 bits, Base64 resorts to padding. To make a 32 bit file compatible with Base64 we'll append 0000 to the end of the file so that the final character can be properly rendered by Base64. Here is the new bit string: 111111 110011 001000 110011 000010 100000. Let's view it in a table format too:
| Bytes | Base64 character |
|---|---|
111111 | / |
110011 | z |
001000 | I |
110011 | z |
000010 | C |
100000 | g |
That's much better. Now the first 6 characters match. But what about the == at the end? We have no bits remaining. In fact, = isn't even in the Base64 table! What gives?
Base64 requires that the number of characters outputted be divisible by 4. This means that those = are padding characters to satisfy that requirement. But why does that requirement exist? Well, let's hypothesize a bit here. Base64 characters use 6 bits each. A byte uses 8 bits. Bytes are fundamental building blocks in a file system. We don't measure things in bits, but rather in bytes. So how many Base64 characters does it take so that the total number of bits fit neatly into a string of bytes (i.e., is divisible by 8)?
It takes 24 bits, which is 3 bytes. And there are 4 Base64 characters (of 6 bits each) in 24 bits. I suppose this was the rationale behind the = padding requirement.
Here is a table that displays how the original file size affects the Base64 output:
| Original file size | # of Base64 characters | = padding | 0 padding |
|---|---|---|---|
| 1 byte | 4 | == | 0000 |
| 2 bytes | 4 | = | 00 |
| 3 bytes | 4 | ||
| 4 bytes | 8 | == | 0000 |
| 5 bytes | 8 | = | 00 |
| 6 bytes | 8 | ||
| ... | ... | ... | ... |
Let's walk through some examples of strings that both require padding and do not require it.
2 = of padding: @ (01000000)
| Bytes | UTF-8 character |
|---|---|
01000000 | @ |
| Bytes | Bit positions | Base64 character |
|---|---|---|
010000 | 010000 00 | Q |
000000 | 010000 00 | A |
padding | none | = |
padding | none | = |
Notice that since there were only 2 bits to use at the end, 0000 was used as padding to the end to make the bit length (excluding any = padding) divisible by 6.
1 = of padding: AB (0100000101000010)
| Bytes | UTF-8 character |
|---|---|
01000001 | A |
01000010 | B |
| Bytes | Bit positions | Base64 character |
|---|---|---|
010000 | 010000 0101000010 | Q |
010100 | 010000 010100 0010 | U |
001000 | 010000010100 0010 | I |
padding | none | = |
This time 00 was used as padding at the end of the string.
No padding: v3c (011101100011001101100011)
| Bytes | UTF-8 character |
|---|---|
01110110 | v |
00110011 | 3 |
01100011 | c |
| Bytes | Bit positions | Base64 character |
|---|---|---|
011101 | 011101 100011001101100011 | d |
100011 | 011101 100011 001101100011 | j |
001101 | 011101100011 001101 100011 | N |
100011 | 011101100011001101 100011 | j |
No 0s needed as padding this time since the number of bits was divisible by 6.
Now we should be able to understand when padding is required and when it isn't. Let's take a look at the completed table of file4.txt (the Base64 representation of file3.txt):
Raw binary of file3.txt (4 bytes in total): 11111111001100100011001100001010
| Bytes | Bit positions | Base64 character |
|---|---|---|
111111 | 111111 11001100100011001100001010 | / |
110011 | 111111 110011 00100011001100001010 | z |
001000 | 111111110011 001000 11001100001010 | I |
110011 | 111111110011001000 110011 00001010 | z |
000010 | 111111110011001000110011 000010 10 | C |
100000 | 111111110011001000110011000010 10 | g |
padding | none | = |
padding | none | = |
Since file3.txt is 4 bytes, it required 0000 as padding for the last Base64 character and == as padding for the complete Base64 output.
One last thing to be aware of is that file4.txt, whose contents are /zIzCg==, will be stored as UTF-8 (which will be the exact same as ASCII in this instance since Base64 is a subset of the ASCII alphabet). Remember that Base64 isn't a character encoding! It's a binary-to-text encoding. Character encodings are the ones that are stored on disk. One mistaken assumption I had while learning this was that the Base64 file would have the exact same bytes on disk as the original file (i.e., file4.txt and file3.txt would have the same bytes). However this is not the case! Observe:
$ xxd -b file4.txt
00000000: 00101111 01111010 01001001 01111010 01000011 01100111 /zIzCg
00000006: 00111101 00111101 00001010 ==.
So Base64 took the underlying bits of file3.txt, used its algorithm to map those to Base64 characters, and then wrote those characters to file4.txt in UTF-8. If we created a new file and manually typed in /zIzCg==, it would have the exact same binary representation. This is simply a UTF-8 encoding of text.
What is Base64url?
Base64url is something that will occasionally show up. This is a variant on Base64 where + and / are replaced with - and _ so that the output will be URL-safe. + and / must be encoded in a URL (i.e., + becomes %2B, / becomes %2F), but - and _ are considered safe.
= is also not URL-safe, but there is no standardization on how to handle it. Some libraries will percent-encode it (%3D) and some will encode it as a period (.).
Encoding vs. encryption
For some reason people often mix these two terms up. I think the reason why, specifically when it involves Base64, is because of the HTTP Authorization request header and JWTs. Both of these concepts are security-related and involve Base64 to transform plaintext into seemingly "scrambled" output. As a result, people mistakenly think Base64 encoding is the same thing as encryption.
Well it's not.
Encryption is the process of mathematically transforming plaintext into ciphertext (a bunch of gibberish) using a key (basically just a random number). Depending on the type of encryption used, the only way to transform ciphertext back to plaintext is with that same key (symmetric encryption) or with a different-but-mathematically-related key (asymmetric encryption). The only way to break encryption without the key is through brute force, which depending on the strength of encryption used, could take 6.4 quadrillion years.
Encoding, in the binary-to-text sense, is the process of transforming bits into an output that's human-printable. It's meant to be a trivially reversible process that anyone can do. Even if a different encoding than Base64 were used, there are a pretty finite amount of encodings out there. Brute forcing that would probably take a modern computer a handful of milliseconds to accomplish.
This of course implies that the HTTP Authorization request header and JWTs do not provide any inherent data confidentiality. Not to say that they are useless, but just that encryption is not one of their benefits. Anyone who intercepts those pieces of data can simply decode the Base64 with ease (if they are technically savvy enough to sniff network traffic then the odds are pretty good they also know what Base64 is). Base64 is meant to ensure that you won't have to deal with binary data (i.e., bytes that the standard character encodings don't know how to interpret) or characters like NUL or EOF. It is often used in security-related concepts (such as the PEM format for example), but it is not itself a security technique!
Python uses Unicode strings for encoding
In python 2 there are a class of string literals that are known as unicode strings. They are delineated by prefixing the character u to a string literal (e.g., u'abc'). I am not a fan of the term unicode string because it leads to the confusion that unicode is an encoding. So what exactly does python mean when it refers to unicode strings?
Let's look at some examples in Python 2.7.12:
>>> a = u'abc'
>>> b = u'abcŔŖ'
>>> a
u'abc'
>>> b
u'abc\u0154\u0156'
So we define 2 strings, a and b, which contain the same contents as file1.txt and file2.txt from part 1 did. a is able to be printed out to the console without an issue, but the console can't render ŔŖ at the end of b. Instead those characters are replaced with their unicode code points: \u0154 (U+0154) and \u0156 (U+0156). It appears that the python 2 interpreter can only print strings using ASCII, and not a unicode-compatible encoding.
Let's try explicitly encoding these strings:
>>> a.encode('utf-8')
'abc'
>>> a.encode('ascii')
'abc'
>>> b.encode('utf-8')
'abc\xc5\x94\xc5\x96'
>>> b.encode('ascii')
Traceback (most recent call last):
File "", line 1, in
UnicodeEncodeError: 'ascii' codec can't encode characters in position 3-4: ordinal not in range(128)
String a can be encoded using both ASCII and UTF-8 as expected. Also as expected, encoding string b using ASCII results in an error since neither Ŕ nor Ŗ are ASCII-compatible. And encoding string b using UTF-8 renders a string that is a mix of ASCII characters (what python 2 can handle) and the hex representations of the non-ASCII characters python 2 couldn't handle.
A unicode string in python 2 is just a combination of ASCII-compatible characters and code points (as strings) for the non-ASCII compatible characters. What about python 3? Python 3 got rid of the distinction between a regular string (e.g., abc) and a unicode string (e.g., u'abc'), and just has regular strings without any prefixes. Does this mean there are no unicode strings in python 3?
Let's find out using Python 3.5.2:
>>> a = "abc"
>>> b = 'abcŔŖ'
>>> a
'abc'
>>> b
'abcŔŖ'
Python 3 treats every string as a unicode string, and on top of that, can print non-ASCII compatible characters to the console now. Also the encode() function still works the same:
>>> b.encode('utf-8')
b'abc\xc5\x94\xc5\x96'
The only other question remaining is how to print out the code points?
>>> b.encode('unicode_escape')
b'abc\\u0154\\u0156'
Now readers should have a good idea of what Base64 is and how it works, the difference between encoding and encryption, and what python means by unicode strings. That was a lot to get through! But that is indicative of the complexities and overloaded terms surrounding what an "encoding" is. Hopefully the next time someone talks about needing to encode a string in Unicode, or how their passwords are secure because they're encoded in Base64, you can set them straight.