Decoding the confusing world of encodings (Part 1)
This post originally appeared on dev.to
What is an encoding? Part 1
Have you ever come across some of these statements?
This file is hex encoded
This file uses an ASCII encoding
This string is Unicode encoded
Let's write the output to a UTF-8 encoded file
Our message is safe because it's encoded using Base64
Python uses Unicode strings for encoding
These represent many of the ways the term "encode" is used across the industry. Frankly I found it all really confusing until I set out to write this post! I'm going to address each of these statements and attempt to define and disambiguate exactly what encoding means.
This file is hex encoded
A similar phrase to hex encoding is binary encoding. Personally I don't like the use of the term "encoding" here. Technically an argument could be made that the semantics are correct. However I prefer using the term "representation." It makes encoding less of an overloaded definition. Also, "representation" does a better job (in my mind at least) of describing what is actually happening.
Hexadecimal (abbreviated as hex) and binary are both numeral systems. That's a fancy way of saying, "here's how to represent a number." If you step back and think about it, numbers are funny things. A number seems pretty straightforward, but it's actually an abstract concept. What is the number for how many fingers you have? You could say it's 00001010, 10, or a and all three would be accurate! We learn to say 10 because the easiest and most common numeral system for humans is decimal, also known as base-10. We have 10 fingers and 10 toes, so that makes learning how to count far more intuitive when we are infants.
If we instead applied that ease-of-use criteria to computers we would get binary (or base-2). Why? Because computers fundamentally think of things as being "on" or "off." Computers rely on electrons having either a positive charge or a negative charge to represent 1s and 0s. And it is with these 1s and 0s that the fundamentals of computing are accomplished, such as storing data or performing mathematical calculations.
Great, so we can represent the same number in multiple ways. What use is that? Let's refer back to the number ten. We could represent it in binary (00001010) or in hex (a). It takes eight characters in binary (or four without the padding of 0s), but only one in hex! That's due to the number of symbols each use. Binary uses two: 0 and 1. Hex uses 16: 0-9 and a-f. The difference in representation size was stark enough for just the number ten, but it grows significantly more unequal when using larger numbers. So the advantage is that hex can represent large numbers much more efficiently than binary (and more efficiently than decimal too for that matter).
Let's explore how to turn this theory into practical knowledge. To provide some examples for this post I created two files via the command line: file1.txt and file2.txt. Here are their contents outputted:
$ cat file1.txt
abc
$ cat file2.txt
abcŔŖ
Don't worry about the unfamiliar R characters at the end of file2.txt. I'll go over those details in-depth in the UTF-8 and Unicode sections. For now I will just show the binary and hex representations of each file:
$ xxd -b file1.txt # binary
00000000: 01100001 01100010 01100011 00001010 abc.
$ xxd file1.txt # hex
00000000: 6162 630a abc.
$ xxd -b file2.txt # binary
00000000: 01100001 01100010 01100011 11000101 10010100 11000101 abc...
00000006: 10010110 00001010 ..
$ xxd file2.txt # hex
00000000: 6162 63c5 94c5 960a abc.....
Again we see the compactness of hex on display. file1.txt requires 32 characters to represent in binary, but only 8 in hex. file2.txt requires 64 characters to represent in binary, but only 16 in hex. If we were to use a hex to binary converter we can see how these representations line up with one another.
Let's dissect file1.txt:
| Binary | Hexadecimal | Decimal |
|---|---|---|
01100001 | 61 | 97 |
01100010 | 62 | 98 |
01100011 | 63 | 99 |
00001010 | 0a | 10 |
As mentioned above, binary is the numeral system that computers "understand." The binary representation of these two files are literally how these files are stored in the computer (as what are known as bits, 1s and 0s, on the computer). The hex and decimal representations are just different ways of representing those same bits. We can see that every byte in binary (1 byte is equal to 8 bits) lines up with 2 hex characters. And we can see what those same values would be if they were represented in decimal. For reference, the largest 1 byte binary value is 11111111, which is ff in hex and 255 in decimal. The smallest 1 byte binary value is 00000000, which is 00 in hex and 0 in decimal. But even armed with this understanding of hex and binary, there's still a lot to go. How does all this relate to the contents of file1.txt?
This file uses an ASCII encoding
Remember that these binary, hex, and decimal representations are all of the same number. But we're not storing a number! We're storing abc. The problem is that computers have no concept of letters. They only understand numbers. So we need a way to say to the computer, "I want this character to translate to number X, this next character to translate to number Y, etc..." Enter ASCII.
Back in the day, ASCII was more or less the de facto standard for encoding text written using the English alphabet. It assigns a numeric value for all 26 lowercase letters, all 26 uppercase letters, punctuation, symbols, and even the digits 0-9. Here is a picture of the ASCII table:
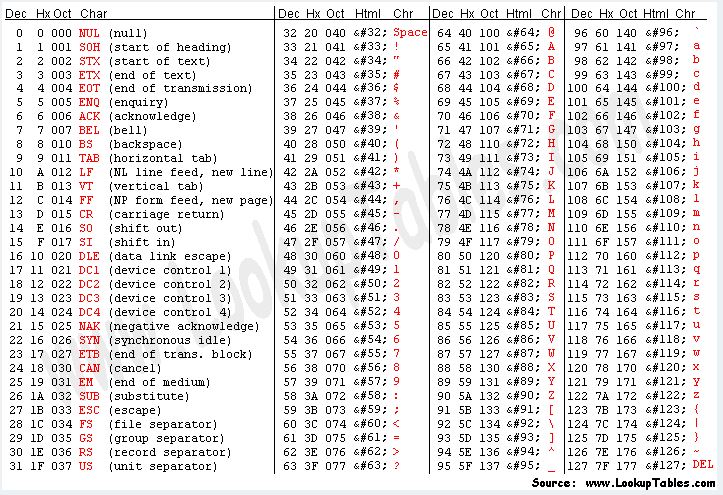
Here is the mapping of file1.txt's hex values to their ASCII characters using the ASCII table:
| Hexadecimal | ASCII |
|---|---|
61 | a |
62 | b |
63 | c |
0a | LF |
We can see a, b, and c there just as we would expect. What is that LF doing there at the end though? LF is a newline character in Unix (standing for "line feed"). I pressed the Return key when editing file1.txt, so that added a newline.
Any character in the ASCII character set requires only 1 byte to store. ASCII supports 128 characters, as we saw in the ASCII table. However, 1 byte allows for 256 (or 28) values to be represented. In decimal that would be 0 (00000000 in binary) through 255 (11111111 in binary). That should mean ASCII can support 128 more characters. Why isn't that the case? ASCII only required 128 characters to support English text and its accompanying symbols so presumably that was all that was taken into account when the ASCII standard was formalized. As a result, ASCII only uses 7 of the 8 bits in a byte. However, that leads to a lot of waste -- half of the values are unused! 128 additional characters could be supported.
Joel Spolsky wrote an excellent blog post on this problem. Basically the issue was fragmentation. Everyone agreed what the first 128 values should map to, but then everyone went and decided their own usage for the remaining 128 values. As a result there was no consistency among different locales.
Let's review what we learned so far. We saw that the computer encodes the string abc into numbers (which are stored as bits). We can then view these bits as the computer has stored it in binary, or we can use different representations such as hex. a becomes 97, b becomes 98, c becomes 99, and the newline character in Unix is 10. ASCII is just a way to map bits (that computers understand) to characters (that humans understand).
ASCII leaves a gaping issue though. There are a lot more than 128 characters in use! What do we do about characters from other languages? Other random symbols? Emojis???
This string is Unicode encoded
As anglocentric as programming is in 2019, English is not the only language that needs to be supported on the web. ASCII is fine for encoding English, but it is incapable of supporting anything else. This is where Unicode enters the fray. Unicode is not an encoding. That point bears repeating. Unicode is not an encoding.
Wikipedia calls it a standard that can be implemented by different character encodings. I find that definition, while succinct, too abstract. Instead, I prefer to think of it like this:
Imagine you have a giant alphabet. It can support over 1 million characters. It is a superset of every language known to humankind. It can support made-up languages. It contains every bizarre symbol you can think of. It has emojis. And all that only fills about 15% of its character set. There is space for much more to be added. However, it's impractical to have a keyboard that has button combinations for over 1 million different characters. The keyboard I'm using right now has 47 buttons dedicated to typeable characters. With the
Shiftkey that number is doubled. That's nowhere close to 1 million though. There needs to be some way to use the characters in this alphabet!
In order to make this alphabet usable we're going to put it in a giant dictionary. A normal dictionary would map words to their respective definitions. In this special dictionary we'll have numbers mapping to all these characters. So to produce the character you want, you will type the corresponding number for it. And then it will be someone else's job to replace those numbers with the characters that they map to in the dictionary. Just as the words are in alphabetical order, the numbers will be in ascending order. And for the characters not yet filled in, we'll just have a blank entry next to the unused numbers.
This is Unicode in a nutshell. It's a dictionary that supports an alphabet of over 1.1 million characters. It does so through an abstraction called a code point. Every character has a unique code point. For example, a has a code point of U+0061. b has a code point of U+0062. And c has a code point of U+0063. Notice a pattern? 61 is the hex value for the character a in ASCII, and U+0061 is the code point for a in Unicode. I'll come back to this point in the UTF-8 section.
The structure of a code point is as follows: U+ followed by a hex string. The smallest that hex string could be is 0000 and the largest is 10FFFF. So U+0000 is the smallest code point (representing the Null character) and U+10FFFF is the largest code point (currently unassigned). As of Unicode 12.0.0 there are almost 138,000 code points in use, meaning slightly under 1 million remain. I think it's safe to say we won't be running out anytime soon.
ASCII can map bits on a computer to the English alphabet, but it wouldn't know what to do with Unicode. So we need a character encoding that can map bits on a computer to Unicode code points (which in turn maps to a giant alphabet). This is where UTF-8 comes into play.
Let's write the output to a UTF-8 encoded file
UTF-8 is one of several encodings that support Unicode. In fact, the UTF in UTF-8 stands for Unicode Transformation Format. You may have heard of some of the others: UTF-16 LE, UTF-16 BE, UTF-32, UCS-2, UTF-7, etc... I'm going to ignore all the rest of these though. Why? Because UTF-8 is by far the dominant encoding of the group. It is backwards compatible with ASCII, and according to Wikipedia, it accounts for over 90% of all web page encodings.
UTF-8 uses different byte sizes depending on what code point is being referenced. This is the feature that allows it to maintain backwards compatibility with ASCII.

Source: Wikipedia
If UTF-8 encounters a byte that starts with 0, it knows it found a starting byte and that the character is only one byte in length. If UTF-8 encounters a byte that starts with 110 then it knows it found a starting byte and to look for two bytes in total. For three bytes it is 1110, and four bytes it is 11110. All continuation bytes (i.e., the non-starting bytes; bytes 2, 3, or 4) will start with a 10. The reason for these continuation bytes is that it allows you to be able to find the starting byte of a character easily.
As a refresher, this is what file2.txt looks like on the command line:
$ cat file2.txt
abcŔŖ
$ xxd -b file2.txt # binary
00000000: 01100001 01100010 01100011 11000101 10010100 11000101 abc...
00000006: 10010110 00001010 ..
$ xxd file2.txt # hex
00000000: 6162 63c5 94c5 960a abc.....
Let's dissect file2.txt to understand how UTF-8 works:
| Hexadecimal | UTF-8 | Unicode Code Point |
|---|---|---|
61 | a | U+0061 |
62 | b | U+0062 |
63 | c | U+0063 |
c594 | Ŕ | U+0154 |
c596 | Ŗ | U+0156 |
0a | LF | U+000A |
We can see that the hex representations for a, b, c, and LF are the same as for file1.txt, and that they align perfectly with their respective code points. The hex representations for Ŕ and Ŗ are twice as long as the other hex representations though. This means that they require 2 bytes to store instead of 1 byte.
Here is a table showing the different representations and the type of byte side-by-side:
| Byte type | Binary | Hexadecimal | Decimal | UTF-8 |
|---|---|---|---|---|
| Starting Byte | 01100001 | 61 | 97 | a |
| Starting Byte | 01100010 | 62 | 98 | b |
| Starting Byte | 01100011 | 63 | 99 | c |
| Starting Byte | 11000101 | c5 | 197 | Ŕ |
| Continuation Byte | 10010100 | 94 | 148 | Ŕ (contd.) |
| Starting Byte | 11000101 | c5 | 197 | Ŗ |
| Continuation Byte | 10010110 | 96 | 150 | Ŗ (contd.) |
| Starting Byte | 00001010 | 0a | 10 | LF |
UTF-8 uses 1 byte to encode ASCII characters, and multiple bytes to encode non-ASCII characters. To be precise it uses 7 bits to encode ASCII characters, exactly like ASCII does. Every byte on disk that maps to an ASCII character will map to the exact same character in UTF-8. And any other code point outside of that range will just use additional bytes to be encoded.
As I alluded to earlier, the code points for a, b, and c match up exactly with the hex representations of those letters in ASCII. I suppose that the designers of Unicode did this in the hopes that it would make backwards compatibility with ASCII easier. UTF-8 made full use of this. Its first 128 characters require one byte to encode. Despite having room for 128 more characters in its first byte, UTF-8 instead required its 129th character to use 2 bytes. DEL is the 128th character (#127 on the page because the table starts at 0) and has the hex representation 7F, totalling 1 byte. XXX (no, not the character for porn) is the 129th character and has the hex representation C280, totalling 2 bytes.
If you're curious here are examples of characters requiring over 2 bytes:
Just to re-emphasize what is happening here: UTF-8 maps bytes on disk to a code point. That code point maps to a character in Unicode. A different encoding, like UTF-32 for example, would map those same bytes to a completely different code point. Or perhaps it wouldn't even have a mapping from those bytes to a valid code point. The point is that a series of bytes could be interpreted in totally different ways depending on the encoding.
That's it for part 1. We covered numeral systems like hex and binary (which I like to call representations instead of encodings), different character encodings such as ASCII and UTF-8, and what Unicode is (and why it's not an encoding). In part 2 we'll address the remaining points and hopefully clear up the confusion surrounding the term "encoding."